寻找最优学习率的方法以及周期性学习率更新策略(论文笔记)
Cyclical Learning Rates for Training Neural Networks
Cyclical Learning Rates for Training Neural Networks 论文笔记。
学习Jeremy Howard的MOOC课程fast.ai2018和fast.ai2019的时候,印象最深的就是fast.ai库的训练速度之快。每次开场,Jeremy老师都要拿出这篇Cycical论文出来说道一波。从每个课件jupyter必备的函数learn.lr_find(),就能看出这篇论文占据了fast.ai一席之地。
一直都想用fast.ai用来做自己的项目,可是它到现在都只是能够训练CV里的分类网络(捎带一下分割网络),就是迟迟不来用在目标检测上的框架,手动DIY实在是太难了!!!
没办法,fast.ai之所以fast的思想还是需要掌握,今天把这篇论文给看了,写个笔记做个总结。结果网上已经出了一大堆根据这篇论文写的关于寻找最优学习率的博客,那就拿来主义,做份摘录好了。谢谢参考下的所有博客!
这篇论文讲的是实操技巧,作者还没有挖掘现象背后的理论解释。
最优学习率?学习率的更新策略?
最优学习率?
开源的几个著名的深度学习CV工具包,Detectron、Maskrcnn_benchmark等,虽然提供参考的配置模板,但里面的学习率都是对应于Pascal VOC、COCO这些数据集,应用在自定义数据集上的可用性又低了一个档次。所以要自己选择一个合适的学习率。
比较笨的方法么就是靠不停地迭代实验进行测试的,就是试错嘛。试错的代价嘛,就是浪费时间啊。
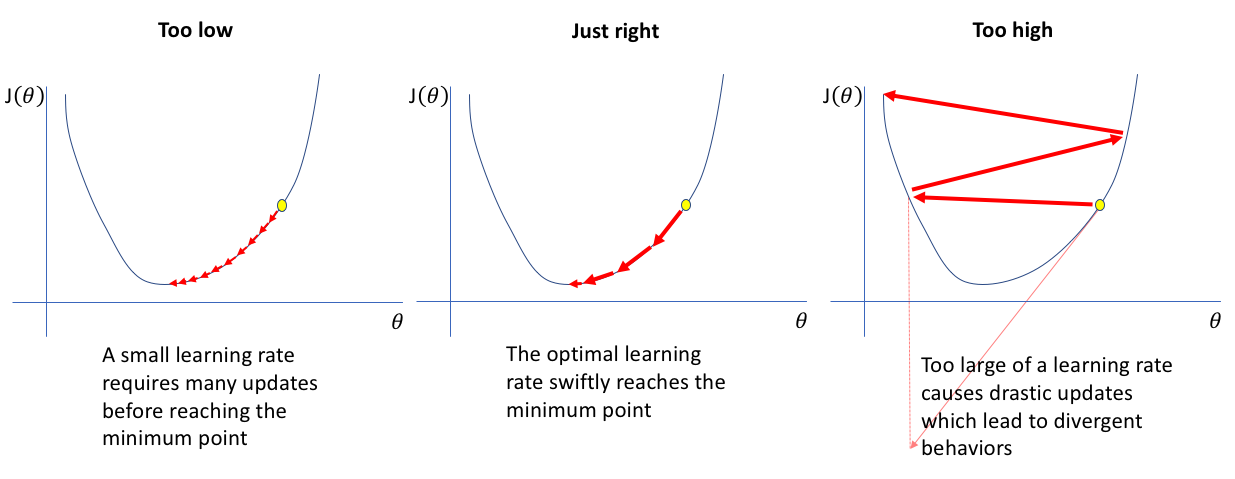
学习率设置得低,自然稳扎稳打,训练可靠,但是收敛的速度很慢很慢;
学习率设置得高,训练速度就算上来了,最终还是容易从震荡到发散,优化等于没有意义。
所以有一个好的学习率,或者初始学习率还是蛮重要的。
学习率的更新策略?
网络的整个学习过程不是一成不变的,刚开始Loss会有较大幅度的下降,等到训练一段时间以后,参数的梯度变小了,要想继续优化,也应当变小参数的更新幅度。所以都会在训练中随着训练慢慢降低学习率。
常见的一些学习率更新策略包括,步进式的(Step Decay),余弦式的(Cosine Decay)等,还有一些是自适应学速率比如RMSProp、AdaDelta、AdaSecant、ESGD等,这些呢,都是通过在训练过程中,通过权重、梯度等信息计算出来的。
这篇论文的作者发现并总结了一个新的学习率的更新策略,称之为Cyclical Learning Rates(周期性学习率),简称CLR,并且取得了不错的训练效果。

最优学习率
整篇文章其实介绍了两个重要的点:
- 周期性学习率的介绍和几个参数设置
- 周期性学习率的上界和下界的设置(最优学习率的查找)
周期性学习率(Cyclical Learning Rates)
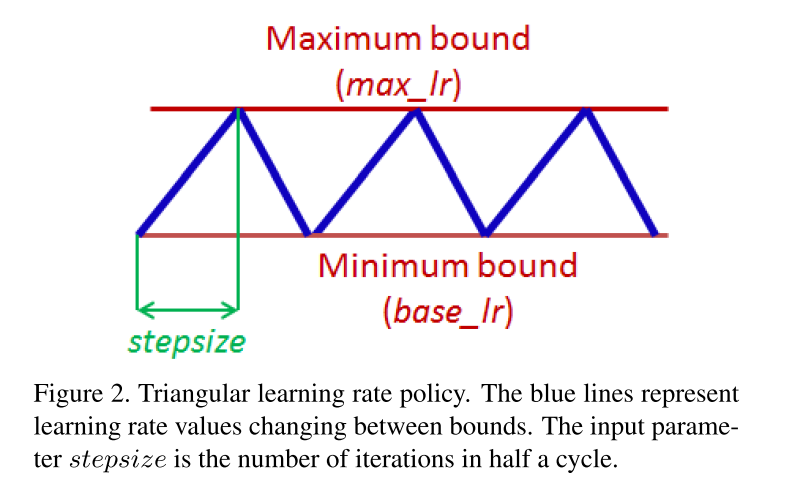
看图就很容易明白:
- 周期性的;
- 学习率值在两个约束值(max_lr和min_lr)之间变化;
- 图示是三角形的更新规则,称之为Triangular learning rate policy.
这种方式的优越性在哪里?
作者也提到了:最小化训练损失的难点不在于局部最小值(local minima),而在于鞍点(saddle points),因为鞍点这个区域具有小的梯度值,减慢了训练的过程。直观的解释就是周期性的学习率能够在上升学习率的时候较快的穿过这个区域。
计算公式
1 | cycle = np.floor(1+iterations/(2*step_size)) # 当前iteration 处于第几个cycle |
拿CIFAR-10来举例,共有50000张图像,设置BatchSize为100,则$epoch = 50000/100=500 iterations$.
设置$step_size$为2-10倍的iterations。step_size表示cycle的一般。
周期性学习率的几种形式
triangular

计算方式
1 | cycle = np.floor(1+iterations/(2*step_size)) |
triangular2(固定周期衰减)
如图,最高点学习率每轮都减半。

计算方式
1 | cycle = np.floor(1+iterations/(2*step_size)) |
exp_range(指数周期衰减)
如图,最高点学习率每轮都乘以一个gamma因子。

计算方式
1 | cycle = np.floor(1+iterations/(2*step_size)) |
选择合理的maximum和minimum边界值
就是如何选择最优的学习率的问题。
其实作者提出的办法还是很简单的,就是不断地迭代,每次迭代使用不同的学习率lr,记录下每次迭代的损失值loss,通过绘制(loss-lr)曲线来观察选择合适的学习率。
如图所示,从一个较低的或者说极低的学习率开始训练网络,并且在每个迭代中慢慢提高学习率(指数式):

每次迭代都记录下当前的学习率和训练loss,结束后根据这俩数据绘制loss-learningrate的曲线,如图:
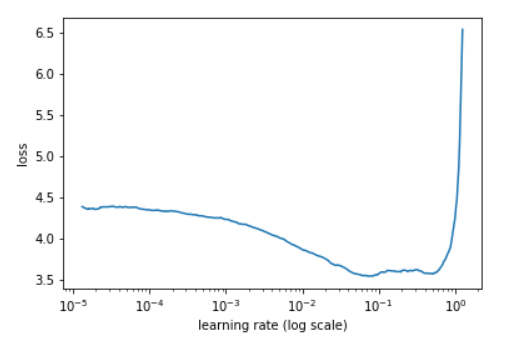
接下来要确定最优的学习率:
论文的作者记录的是accuracy-lr曲线,然后他是从accuracy开始上升到开始下降这段区间,用这个区间来确定min_lr和max_lr。
按照图示就是绿色区间的首尾横坐标。![area]()
如果要用最优学习率的话,就取max_lr的1/3或1/4,用fast.ai Jeremy 的话讲就是loss曲线下降最快的地方。
附上一份PyTorch实现寻找学习率的代码,可以根据自己情况修改:
1 | def find_lr(init_value = 1e-8, final_value=10., beta = 0.98): |
代码来自博客How Do You Find A Good Learning Rate。